Extract API JSON Output Format
Overview
The JSON output of the Extract API consists of two main components: the content and the annotations.
Content is what's in the document. These are the items you can find in the document, for example: paragraphs, headings, titles, figures, and miscellaneous text. Content consists of the type of content it is as well as its text.
Annotations are table structures that represent the relationship between table cells, including the positions so that you can "build" the table from its smallest parts.
There are IDs linking the annotations back to its associated content.
Let's dive into the structure of the JSON.
Overall Structure
The specific dictionary captured in this JSON contains the two overall components we mentioned above. It has two keys: content_tree and annotations.
Content Tree
The content tree contains the text content of the document, whether it's found directly as text or within a table or title. It has a tree structure, meaning each item may have "children", to represent hierarchical structure of the document. The highest level is a DOCUMENT, which contains everything as its children. Under the DOCUMENT, there can be other hierarchical structures, e.g. a header-level 2 H2 can be a child of a header-level 1 H1, and a paragraph and a miscellaneous text can be children of this H2. There can be more complex structures like a table has all its own table cells as its children.
Please note that only when document_type is broker_research we have hierarchical structure for texts not from tables. When document_type is general, only tables have table cells as its "children".
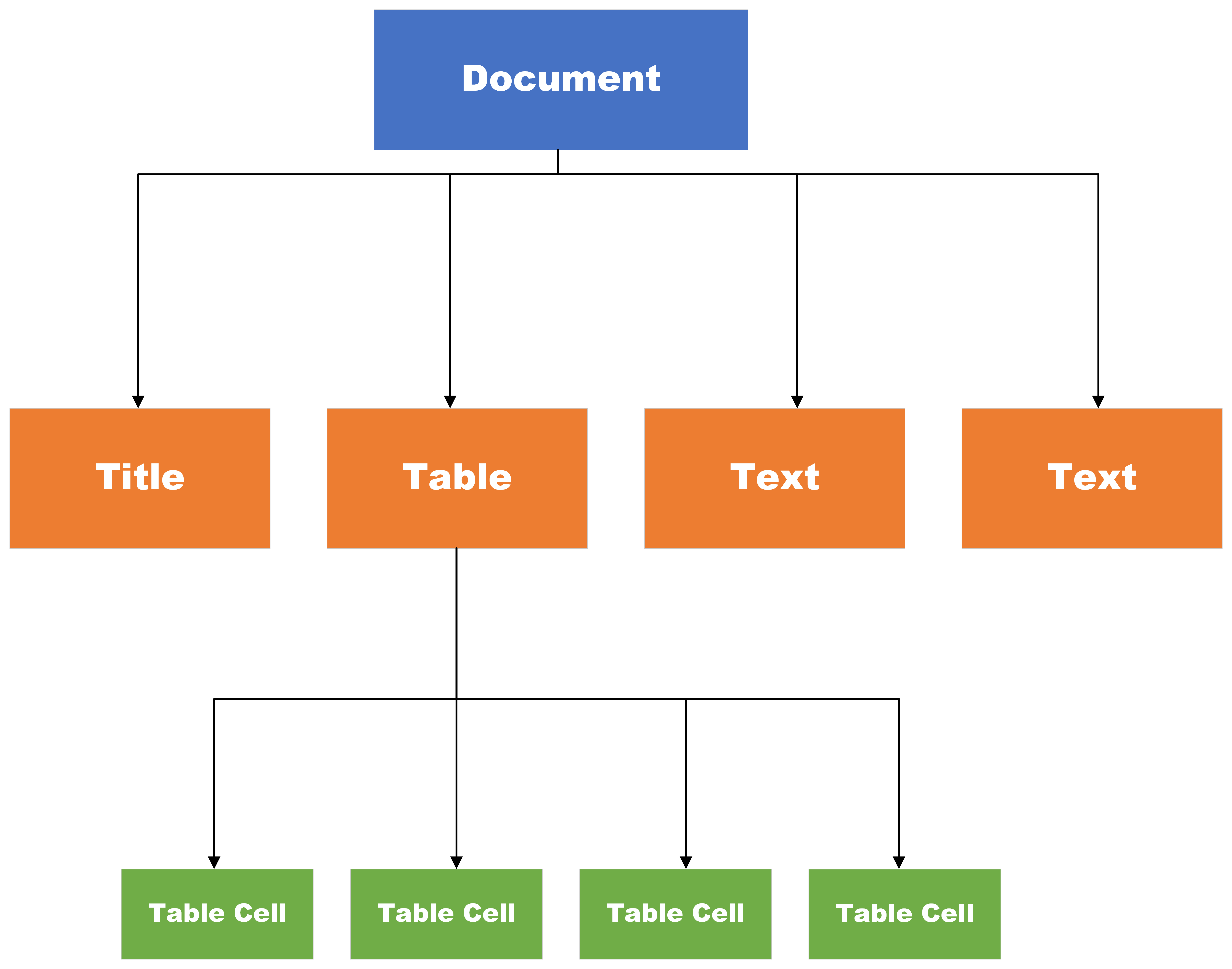
The types are as follows:
content_tree: Dict[str, Any]Keys:
children: List[Dict[str, Any]] # recursively contains more dicts with children
content: str # text
type: str
uid: str # unique IDwhen document_type is broker_research, type can be one of
'DOCUMENT',
'PARAGRAPH',
'H1',
'H2',
'TABLE_CELL',
'TABLE',
'TABLE_TITLE',
'FIGURE_TITLE',
'TEXT',when document_type is general, type can be one of
'DOCUMENT',
'TABLE_CELL',
'TABLE',
'TEXT',
'TITLE'Annotations
Annotations are a list of dictionaries, each of which maps back to the content they relate to as well as contains some useful information about the content. For example, annotations can be relationships between the different table cells in order to know how to put them together into a larger table. Each table cell annotation would tell you where a cell is (row and column) and how much it spans.
The types are as follows:
annotations: List[Dict[str, Any]]Keys:
content_uids: List[str] # unique ID that maps to content uids
type: str # 'table_structure'
data: Dict[str, List[int]] # contains indices and span of the cellKeys for "data":
index: [int, int] # row and column in the table
span: [int, int] # how much the cell spansConnecting The Dots
Let's see an example that will help us make sense of how the UI output, annotations, and content tree all work together.
Here is an example image in the UI:

As you can see, there's a table. But what does that look like in the JSON output?
Let's start at the top level of the content tree:
>>> output['content_tree']['type']
'DOCUMENT'This is the overall document. We must go down to its children to find the text, titles, and tables.
>>> output['content_tree']['children'][5]['type']
'TABLE'Here we have a table. This table contains children - its cells:
>>> output['content_tree']['children'][5]['children']
[{'children': [], 'content': '2048', 'type': 'TABLE_CELL', 'uid': '133'}, {'children': [], 'content': '4096', 'type': 'TABLE_CELL', 'uid': '134'}, {'children': [], 'content': 'Methods', 'type': 'TABLE_CELL', 'uid': '135'}, {'children': [], 'content': 'Extrapolation', 'type': 'TABLE_CELL', 'uid': '136'}, {'children': [], 'content': 'ROPE', 'type': 'TABLE_CELL', 'uid': '137'}, {'children': [], 'content': '73.6', 'type': 'TABLE_CELL', 'uid': '138'}, {'children': [], 'content': '294.45', 'type': 'TABLE_CELL', 'uid': '139'}, {'children': [], 'content': 'ROPE + BCA', 'type': 'TABLE_CELL', 'uid': '140'}, {'children': [], 'content': '25.57', 'type': 'TABLE_CELL', 'uid': '141'}, {'children': [], 'content': '25.65', 'type': 'TABLE_CELL', 'uid': '142'}, {'children': [], 'content': 'Alibi', 'type': 'TABLE_CELL', 'uid': '143'}, {'children': [], 'content': '23.14', 'type': 'TABLE_CELL', 'uid': '144'}, {'children': [], 'content': '24.26', 'type': 'TABLE_CELL', 'uid': '145'}, {'children': [], 'content': 'Alibi + BCA', 'type': 'TABLE_CELL', 'uid': '146'}, {'children': [], 'content': '24.6', 'type': 'TABLE_CELL', 'uid': '147'}, {'children': [], 'content': '25.37', 'type': 'TABLE_CELL', 'uid': '148'}, {'children': [], 'content': 'XPOS (Ours)', 'type': 'TABLE_CELL', 'uid': '149'}, {'children': [], 'content': '22.56', 'type': 'TABLE_CELL', 'uid': '150'}, {'children': [], 'content': '28.43', 'type': 'TABLE_CELL', 'uid': '151'}, {'children': [], 'content': 'XPOS + BCA (Ours)', 'type': 'TABLE_CELL', 'uid': '152'}, {'children': [], 'content': '21.6', 'type': 'TABLE_CELL', 'uid': '153'}, {'children': [], 'content': '20.73', 'type': 'TABLE_CELL', 'uid': '154'}]Nice! We have all the cells that comprise the table. Let's examine an example cell more closely:
>>> output['content_tree']['children'][5]['children'][0]
{'children': [], 'content': '2048', 'type': 'TABLE_CELL', 'uid': '133'}The content indicates that the text in this cell is "2048", and it has no children (i.e. this is the smallest unit - a single table cell). To check if there are annotations associated with this cell - which would allow us to be able it connect it to other cells - we must find a uid to content_uid match. Here it is:
>>> output['annotations'][126]
{'content_uids': ['133'], 'data': {'index': [0, 1], 'span': [1, 1]}, 'type': 'table_structure'}Here, we have the annotation of that cell (row 0, column 1, one cell) and its corresponding content ID.
If we go through all the annotations, we will find one for each of the content_uids, which will tell us which row and column the cell is in. That way we have the text in each cell - in the content - as well as their relationship to each other - in the annotations.
See the Table Extraction page for further information on rebuilding tables.
Location Bounding Boxes
By default, the output JSON does not return any bounding box information for the content or annotations. However, a simple kwarg to requests.get will add this to the output JSON dictionary. Replace the the usual requests get call with the following:
response = requests.get(response_url, params={"output_format": "structured_document_with_locations"}, headers=headers)
This adds a new key to the dictionary called "locations" within annotations and contents. "locations" is a list of dictionaries with the following keys:
page_number: int # Page number where the content or annotation is found (0-indexed)
height: float # Normalized height of the bounding box
width: float # Normalized width of the bounding box
x: float # Normalized x0 of the bounding box (left)
y: float # Normalized y0 of the bounding box (top)"locations" is a list to allow for multiple locations associated with an annotation or content. "locations" will be None if it's associated with a higher-level object like a document page, but its children will each contain a locations entry.
These are page-relative locations. To convert to bounding box coordinates on your own rendered page, use (page_width*x, page_height*y, page_width*(x+width), page_height*(y+height)).
Character Offsets
Some use cases, such as those involving visual rendering, require character locations. The output format structured_document_with_char_offsets includes this information:
response = requests.get(response_url, params={"output_format": "structured_document_with_char_offsets"}, headers=headers)
It will include locations as mentioned above as well as a new dictionary key text_node_data. text_node_data is a dictionary with the following keys and values:
texts: list[str] # List of all the strings in the bounding boxes that form the segment bounding box
text_locations: list[dict[str, float | int]] # List of locations in the same format as the overall segment's location, namely a dictionary with page_number, height, width, x, and y
character_offsets: list[list[float]] # List of relative locations of characters in the bounding box. These are normalized between 0 and 1 and correspond to the same indexed text box in `texts`/`text_locations`To understand this output format better, it's worth highlighting that Extract's output contains segments of certain categories, such as tables and paragraphs. There are smaller bounding boxes of text that can make up a larger segment. The default output format only has the segment-level information. For specialized use cases, however, you can use this output format to have all the individual text boxes with the locations of each character in each box.
One important note: the character offsets are based on graphemes rather than the underlying unicode values. This is particularly important for non-Latin based characters such as those in Arabic, Mandarin, and Thai. In these languages, a single character like ต in Thai may have multiple unicode values, but it is treated as a single grapheme with a single character offset in Extract.
We determine the graphemes of a text and therefore the character offsets using this library: ugrapheme (opens in a new tab)